Redis管道-Pipeline
管道的由来
正常情况下,当我们使用Redis客户端执行多条时,会与服务端有多次网络IO交互。
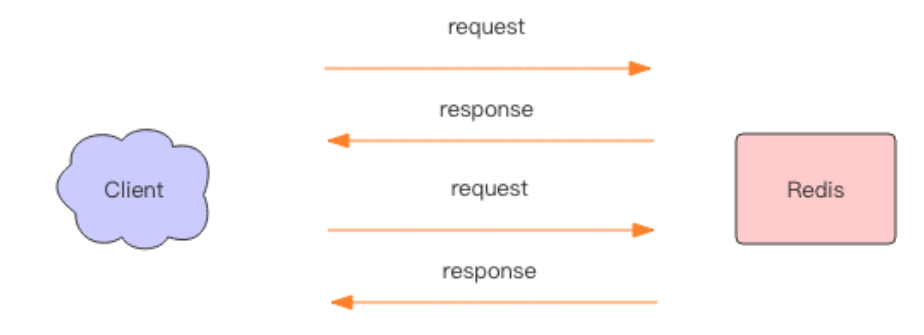
这样的一个网络IO过程称为Round trip time(简称RTT, 往返时间),mget mset有效节约了RTT,但大部分命令(如hgetall,并没有mhgetall)不支持批量操作,需要消耗N次RTT 。当执行多条命令的时候都需要等待上一条命令执行完毕才能执行。通过对上面过程的了解,实际上客户端是经历了写-读-写-读四个操作才完整地执行了两条指令。

如果我们调整下读写顺序,改成写-写-读-读,这两个指令同样可以正常完成。两个连续的写操作和两个连续的读操作总共只会花费一次网络来回,就好比连续的write 操作合并了,连续的read操作也合并了一样。
这便是管道操作的本质,服务器根本没有任何区别对待,还是收到一条消息,执行一条消息,回复一条消息的正常的流程。客户端通过对管道中的指令列表改变读写顺序就可以大幅节省 IO 时间。
使用场景
有些系统可能对可靠性要求很高,每次操作都需要立马知道这次操作是否成功,是否数据已经写进redis了,那这种场景就不适合,因为Pipeline是非原子性操作。另外Pipeline在某些场景下非常有用,比如有多个指令需要被“及时的”提交,而且他们对响应结果没有互相依赖,对结果响应也无需立即获得。在Pipeline期间将“独占”链接,此期间将不能进行非“管道”类型的其他操作,直到 Pipeline 关闭。
管道的本质
我们先分析下一个请求交互的流程,如图
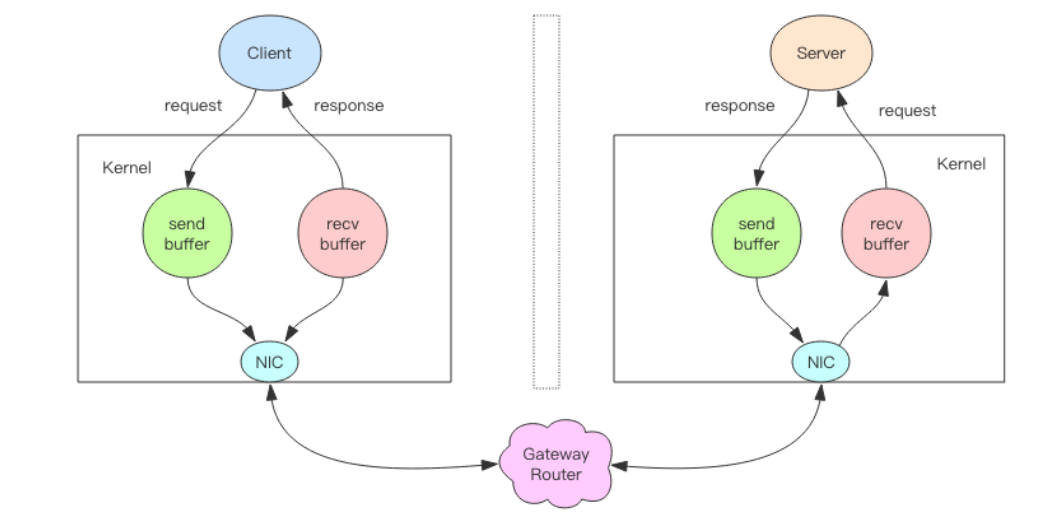
- 客户端进程调用 write 将消息写到操作系统内核为套接字分配的发送缓冲 send buffer
- 客户端操作系统内核将发送缓冲的内容发送到网卡,网卡硬件将数据通过「网际路由」送到服务器的网卡
- 服务器操作系统内核将网卡的数据放到内核为套接字分配的接收缓冲 recv buffer
- 服务器进程调用 read 从接收缓冲中取出消息进行处理
- 服务器进程调用 write 将响应消息写到内核为套接字分配的发送缓冲 send buffer
- 服务器操作系统内核将发送缓冲的内容发送到网卡,网卡硬件将数据通过「网际路由」送到客户端的网卡
- 客户端操作系统内核将网卡的数据放到内核为套接字分配的接收缓冲 recv buffer
- 客户端进程调用 read 从接收缓冲中取出消息返回给上层业务逻辑进行处理
write操作
write操作只负责将数据写到本地操作系统内核的发送缓冲sendbuffer然后就返回了。剩下的事交给操作系统内核异步将数据送到目标机器。但是如果发送缓冲满了,那么就需要等待缓冲空出空闲空间来,这个就是写操作 IO 操作的真正耗时。
read操作
read 操作只负责将数据从本地操作系统内核的接收缓冲recv buffer中取出来就完事了。但是如果缓冲是空的,那么就需要等待数据到来,这个就是读操作 IO 操作的真正耗时。
像redis.get(key)这样一个简单的请求来说,write 操作几乎没有耗时,直接写到发送缓冲就返回,而 read 就会比较耗时了,因为它要等待消息经过网络路由到目标机器
处理后的响应消息,再回送到当前的内核读缓冲才可以返回。这才是一个网络来回的真正开销。
Pipeline在客户端会将多个命令(默认是53个)放到一个tcp报文一起发送,而服务端会将这多个命令的处理结果放到一个tcp报文返回。在Redis必须在处理完所有命令前,会先缓存起所有命令的处理结果。打包的命令越多,缓存消耗内存也越多。其实现的原理是队列,而队列的原理是先进先出,这样就保证数据的顺序性。
原生批命令(mset、 mget)与Pipeline对比
- 原生批命令是原子性,Pipeline是非原子性
- 原生批命令一命令多个key, 但Pipeline支持多命令(存在事务),非原子性
- 原生批命令是服务端实现,而Pipeline需要服务端与客户端共同完成
总结
Pipeline管道机制不单单是为了减少RTT的一种方式,同时也减少了系统层面用户态、内核态的频繁切换,它实际上大大提高了Redis的QPS。从底层套接字的角度来看,read()和write()系统调用,会从用户态切换到内核态,这种上下文切换开销是巨大。而使用Pipeline的情况下,通常使用单个read()系统调用读取许多命令,然后使用单个write()系统调用返回响应结果,这样就提高了QPS。