基于Redis Bloom Filter 实现防止缓存穿透
概念
布隆过滤器(Bloom Filter)是一个很长的二进制向量和一系列随机映射函数。它可以通过若干个Hash函数将一个元素映射成一个位阵列中的若干个点。这样一来,我们只要看看这若干个点是不是1就可以知道集合中有没有它了,这就是布隆过滤器的基本思想。但是布隆过滤器也不是特别不精确,只要参数设置的合理, 它的精确度可以控制的相对足够精确,只会有小小的误判概率。
利用布隆过滤器我们可以预先把数据查询的主键,比如用户ID或文章ID缓存到过滤器中。当根据ID进行数据查询的时候,我们先判断该ID是否存在,若存在的话,则进行下一步处理。若不存在的话,直接返回,这样就不会触发后续的数据库查询。需要注意的是缓存穿透不能完全解决,我们只能将其控制在一个可以容忍的范围内。
优缺点
优点:优点很明显,二进制组成的数组,占用内存极少,并且插入和查询速度都足够快
缺点:随着数据的增加,误判率会增加;还有无法判断数据一定存在;另外还有一个重要缺点,无法删除数据
原理
存放元素
当我们将一个元素加入布隆过滤器,使用布隆过滤器中的哈希函数对元素值进行计算,得到哈希值(有几个哈希函数得到几个哈希值)。根据得到的哈希值,在位数组中把对应下标的值置为 1判断元素
当我们需要判断一个元素是否存在于布隆过滤器的时候,对给定元素再次进行相同的哈希计算;得到值之后判断位数组中的每个元素是否都为1,如果值都为1,那么说明这个值在布隆过滤器中, 如果存在一个值不为 1,说明该元素不在布隆过滤器中。
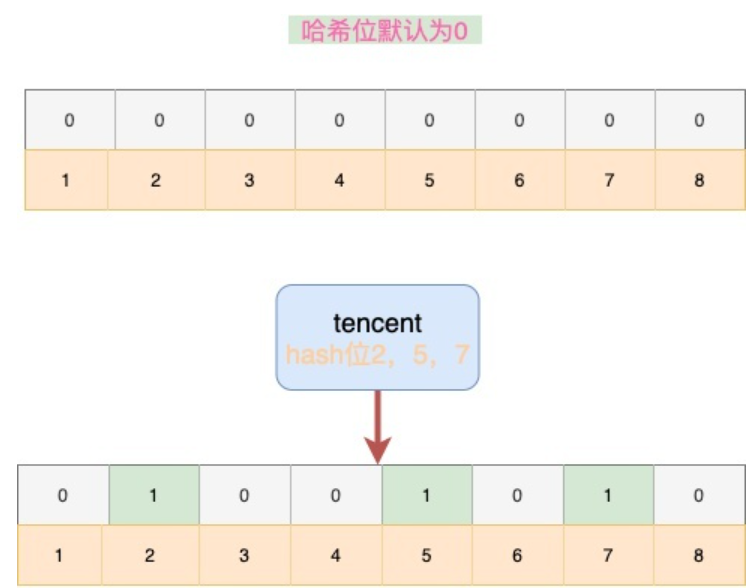
如上图,有8个hash位,且默认值为0,当对tencent进行散列hash之后,2,5,7位被置为1,这时候我们再对其它词汇other进行hash,假设散列为1、2、3,1位为0,可以判断该单词不存在集合中。
操作指令
bf.add
bf.add 添加元素
1 | 127.0.0.1:6379> bf.add users u1 |
bf.exists
bf.exists 查询元素是否存在, 它的用法和 set 集合的 sadd 和 sismember 差不多
1 | 127.0.0.1:6379> bf.exists users u1 |
bf.madd
bf.add 只能一次添加一个元素, 如果想要一次添加多个,就需要用到 bf.madd 指令
1 | 127.0.0.1:6379> bf.madd users user4 user5 user6 |
bf.mexists
如果需要一次查询多个元素是否存在, 就需要用到 bf.mexists 指令
1 | 127.0.0.1:6379> bf.mexists users user4 user5 user6 user7 |
bf.reserve
bf.reserve可以对布隆过滤器进行初始化动作。bf.reserve 有三个参数,分别是key、error_rate (错误率) 和 initial_size。
- error_rate越低,需要的空间越大,对于不需要过于精确的场合,设置稍大一些也没有关系,比如上面说的推送系统,只会让一小部分的内容被过滤掉,整体的观看体验还是不会受到很大影响的
- initial_size 表示预计放入的元素数量,当实际数量超过这个值时,误判率就会提升,所以需要 提前设置一个较大的数值避免超出导致误判率升高。
1 | 127.0.0.1:6379> bf.reserve users 0.01 1000 |
如果不使用bf.reserve,默认的error_rate是0.01,默认的initial_size是100。
如何选择哈希函数个数和布隆过滤器长度
如果布隆过滤器的长度太小,所有的 bit 位很快就会被用完,此时查询误判率比较大; 如果布隆过滤器的长度太大,那么误判的概率会很小,但是内存空间浪费严重。 类似的,哈希函数的个数越多,则布隆过滤器的bit位被占用的速度越快;哈希函数的个数越少,则误判的概率又会上升。因此,布隆过滤器的长度和哈希函数的个数需要根据业务场景来权衡。
三个参数
- 哈希函数的个数k;
- 布隆过滤器位数组的容量m;
- 布隆过滤器插入的数据数量n;
为了获得最优的准确率,当k = ln2 * (m/n)时,布隆过滤器获得最优的准确性