Redis Stream
简介
Redis 本身是有一个 Redis 发布订阅 (pub/sub) 来实现消息队列的功能,但它有个缺点就是消息无法持久化,如果出现网络断开、Redis 宕机等,消息就会被丢弃。而Redis 5.0版本增加了Redis Stream,提供了消息的持久化和主备复制功能,可以让任何客户端访问任何时刻的数据,并且能记住每一个客户端的访问位置,还能保证消息不丢失。
逻辑结构
每个 Stream 都有唯一的名称,它就是 Redis 的 key,在我们首次使用 xadd 指令追加消息时自动创建。每个消息都有一个唯一的 ID 和对应的内容。
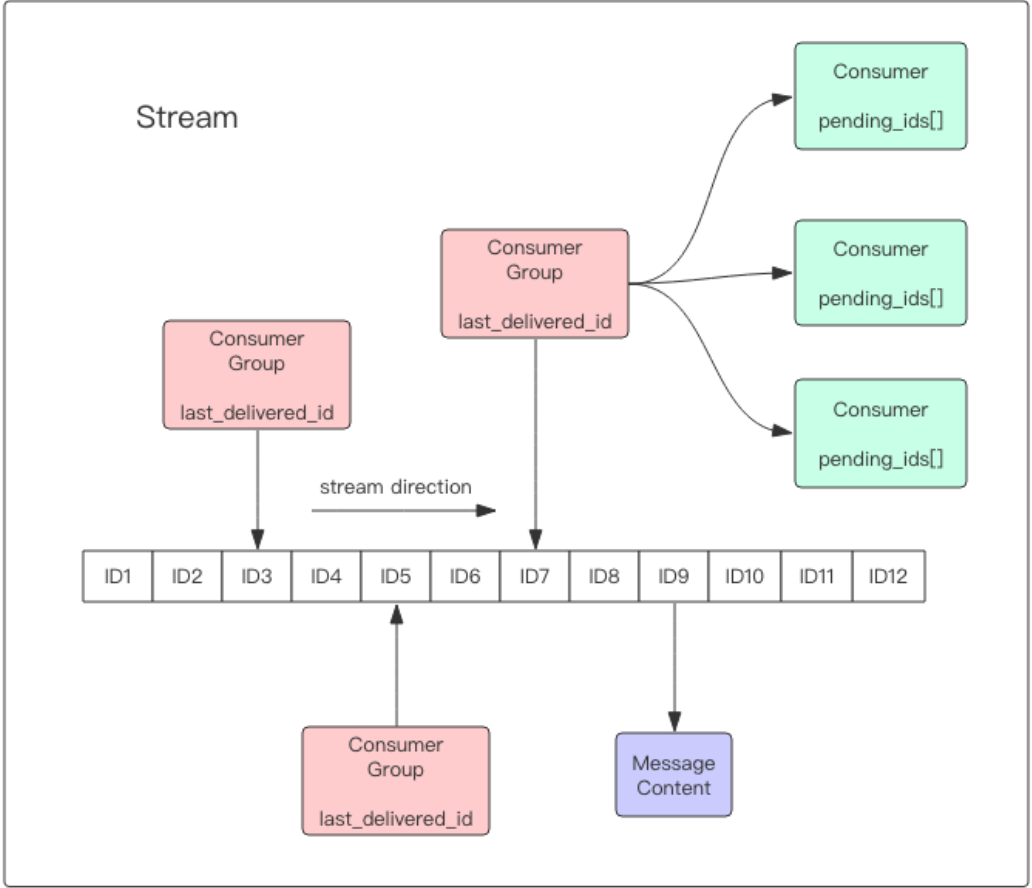
Consumer Group :消费组,使用
XGROUP CREATE命令创建,一个消费组有多个消费者(Consumer)。每个消费组(Consumer Group)的状态都是独立的,相互不受影响。也就是说同一份Stream内部的消息会被每个消费组都消费到。同一个消费组 (Consumer Group) 可以挂接多个消费者 (Consumer),这些消费者之间是竞争关系,任意一个消费者读取了消息都会使游标 last_delivered_id往前移动。last_delivered_id :游标,每个消费组会有个游标 last_delivered_id,任意一个消费者读取了消息都会使游标 last_delivered_id 往前移动。
pending_ids :消费者(Consumer)的状态变量,作用是维护消费者的未确认的id。
pending_ids记录了当前已经被客户端读取的消息,但是还没有ack。如果消费者收到了消息处理完了但是没有回复ack,就会导致pending_ids列表不断增长,如果有很多消费组的话,那么这个pending_ids占用的内存就会放大。
消息 ID
消息 ID 的形式是 timestampInMillis-sequence,例如 1527846880572-5,它表示当前的消息在毫米时间戳 1527846880572 时产生,并且是该毫秒内产生的第 5 条消息。消息 ID 可以由服务器自动生成,也可以由客户端自己指定,但是形式必须是整数-整数,而且必须是后面加入的消息的 ID 要大于前面的消息 ID。
为了保证消息是有序的,由Redis生成的ID是单调递增有序的。由于ID中包含时间戳部分,为了避免服务器时间错误而带来的问题(例如服务器时间延后了),Redis的每个Stream类型数据都维护一个latest_generated_id属性,用于记录最后一个消息的ID。
若发现当前时间戳退后,即小于latest_generated_id,则采用时间戳不变而序号递增的方案来作为新消息ID(这也是序号为什么使用int64的原因,保证有足够多的的序号),从而保证ID的单调递增性质。
消息内容
消息内容就是键值对,形如 hash 结构的键值对。
指令介绍
XADD
XADD,命令用于在某个stream(流数据)中追加消息,演示如下:
1 | 127.0.0.1:6379> XADD memberMessage * user kang msg Hello |
其中语法格式为:
1 | XADD key ID field string [field string ...] |
需要提供key,消息ID方案,消息内容,其中消息内容为key-value型数据。 ID,最常使用*,表示由Redis生成消息ID,这也是强烈建议的方案。 field string [field string], 就是当前消息内容,由1个或多个key-value构成。
另外在XADD的指令提供一个定长长度 maxlen,就可以将老的消息干掉,确保最多不超过指定长度。
1 | 127.0.0.1:6379> xadd codehole maxlen 3 * name xiaorui age 1 |
XREAD
XREAD,从Stream中读取消息,演示如下:
1 | 127.0.0.1:6379> XREAD streams memberMessage 0 |
上面的命令是从消息队列memberMessage中读取所有消息。XREAD支持很多参数,语法格式为:
1 | XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] ID [ID ...] |
其中:
- [COUNT count],用于限定获取的消息数量
- [BLOCK milliseconds],用于设置XREAD为阻塞模式,默认为非阻塞模式
ID,用于设置由哪个消息ID开始读取。使用0表示从第一条消息开始。消息队列ID是单调递增的,所以通过设置起点,可以向后读取。在阻塞模式中,可以使用$,表示最新的消息ID。(在非阻塞模式下$无意义)。
XRED读消息时分为阻塞和非阻塞模式,使用BLOCK选项可以表示阻塞模式,需要设置阻塞时长。非阻塞模式下,读取完毕(即使没有任何消息)立即返回,而在阻塞模式下,若读取不到内容,则阻塞等待。
一个典型的阻塞模式用法为:
1 | 127.0.0.1:6379> XREAD block 1000 streams memberMessage $ |
我们使用Block模式,配合$作为ID,表示读取最新的消息,若没有消息,命令阻塞!等待过程中,其他客户端向队列追加消息,则会立即读取到。
因此,典型的队列就是 XADD 配合 XREAD Block 完成。XADD负责生成消息,XREAD负责消费消息。
XGROUP、XREADGROUP
- XGROUP,用于管理消费者组,提供创建组,销毁组,更新组起始消息ID等操作
- XREADGROUP,分组消费消息操作
1 | XREADGROUP GROUP mqGroup consumerA COUNT 1 STREAMS mq > |
用于组mqGroup内消费者consumerA在队列mq中消费,参数>表示未被组内消费的起始消息,参数count 1表示获取一条。语法与XREAD基本一致,不过是增加了组的概念。
可以进行组内消费的基本原理是,STREAM类型会为每个组记录一个最后处理(交付)的消息ID(last_delivered_id),这样在组内消费时,就可以从这个值后面开始读取,保证不重复消费。
若某个消费者,消费了某条消息,但是并没有处理成功时(例如消费者进程宕机),这条消息可能会丢失,因为组内其他消费者不能再次消费到该消息了。
XPENDING
为了解决组内消息读取但处理期间消费者崩溃带来的消息丢失问题,STREAM设计了Pending列表,用于记录读取但并未处理完毕的消息。命令XPENDIING用来获消费组或消费内消费者的未处理完毕的消息。
1 | 127.0.0.1:6379> XPENDING mq mqGroup - + 10 consumerA #在加上消费者参数获取具体某个消费者的Pending列表 |
每个Pending的消息有4个属性:
- 消息ID
- 所属消费者
- IDLE,已读取时长
- delivery counter,消息被读取次数
宕机的消费者再次上线后,可以读取该Pending列表,就可以继续处理该消息了,保证消息的有序和不丢失。不过此时 xreadgroup 的起始消息ID 不能为参数>,而必须是任意有效的消息 ID,一般将参数设为 0-0,表示读取所有的PEL 消息以及自 last_delivered_id 之后的新消息。
Stream 的高可用
Stream 的高可用是建立主从复制基础上的,它和其它数据结构的复制机制没有区别,也就是说在 Sentinel 和 Cluster 集群环境下 Stream 是可以支持高可用的。不过鉴于 Redis 的
指令复制是异步的,在 failover 发生时,Redis 可能会丢失极小部分数据,这点 Redis 的其它数据结构也是一样的。
其他消息队列实现方式
基于异步消息队列List lpush-brpop(rpush-blpop)
使用rpush和lpush操作入队列,lpop和rpop操作出队列。
List支持多个生产者和消费者并发进出消息,每个消费者拿到都是不同的列表元素。但是当队列为空时,lpop和rpop会一直空轮训,消耗资源;所以引入阻塞读blpop和brpop(b代表blocking),阻塞读在队列没有数据的时候进入休眠状态,一旦数据到来则立刻醒过来,消息延迟几乎为零。
缺点
- 如果线程一直阻塞在那里,Redis客户端的连接就成了闲置连接,闲置过久,服务器一般会主动断开连接,减少闲置资源占用,这个时候blpop和brpop或抛出异常,所以在编写客户端消费者的时候要小心,如果捕获到异常,还有重试
- 做消费者确认ACK麻烦,不能保证消费者消费消息后是否成功处理的问题(宕机或处理异常等),通常需要维护一个Pending列表,保证消息处理确认
- 不能重复消费,一旦消费就会被删除
- 不支持分组消费
PUB/SUB-订阅/发布模式
PUBLISH-向信道发送消息,此模式允许生产者只生产一次消息,由中间件负责将消息复制到多个消息队列,每个消息队列由对应的消费组消费。
优点
典型的广播模式,一个消息可以发布到多个消费者。消息即时发送,消息不用等待消费者读取,消费者会自动接收到信道发布的消息。
缺点
- 消息丢失,不能寻回
- 不能保证每个消费者接收的时间是一致的
- 若消费者客户端出现消息积压,到一定程度,会被强制断开,导致消息意外丢失。通常发生在消息的生产远大于消费速度时。可见,Pub/Sub模式不适合做消息存储,消息积压类的业务,而是擅长处理广播,即时通讯,即时反馈的业务。
基于Sorted-Set的实现
有序集合的方案是在自己确定消息顺序ID时比较常用,使用集合成员的Score来作为消息ID,保证顺序,还可以保证消息ID的单调递增。通常可以使用时间戳+序号的方案。确保了消息ID的单调递增,利用SortedSet的依据Score排序的特征,就可以制作一个有序的消息队列了。
优点
就是可以自定义消息ID,在消息ID有意义时,比较重要。
缺点
不允许重复消息(因为是集合),同时消息ID序号有错误会导致消息的顺序出错。