基于Redis HyperLogLog实现UV统计功能
背景
最近项目里需要计算每个商品的综合打分分数,以此来作为每个商品的畅销分数,来近实时统计每个商品的畅销排名。这其中需要统计近12个小时每个浏览商品的UV值来作为其中的一个计算项。
选用Redis HyperLogLog原因
因同1个用户的反复操作只统计1次,首先想到就是利用Redis Set结构来进行去重计算。目前商品总数接近90W,DAU接近500W,且因为是近实时,所以每分钟为每个浏览商品生成一个key-uv:{goodsId}:{当前时间戳(分钟)}。我们粗略估算下每分钟每个用户大概浏览10个不同的商品,高峰期大约有100W用户同时在线这样子,那么每小时占用的内存为:10*60*100W * 8byte = 460MB。如果用HyperLogLog算法,占用的内存为:10*60 * 12k = 7MB,远小于使用Set结构来存储。但是HyperLogLog统计结果会存在误差,标准误差大约在0.8%。考虑到可以接受一定的误差并且占用内存小,所以采用了HyperLogLog算法来统计UV。
HyperLogLog特性
HyperLogLog(HLL) 是一种用于基数计数的概率算法,是基于LogLog(LLC)算法的优化和改进,在同样空间复杂度下,能够比LLC的基数估计误差更小。
它具有以下特性:
- HyperLogLog使用极少的内存就能统计大量的数据,如Redis HyperLogLog,只需要12K内存就能统计2^64个数据,远比Hash结构的内存开销要少
- 计数存在一定的误差,误差率整体较低。标准误差为 0.81%
- 误差可以被设置辅助计算因子进行降低
HyperLogLog算法解析
HyperLogLog算法来源于著名的伯努利试验。
伯努利试验
伯努利试验是数学概率论中的一部分内容,它的典故来源于抛硬币,我们每次抛硬币出现正反面的概率各自是50%。试验过程如下:假设一直抛硬币,直到它出现正面为止,我们记录为一次完整的试验,这中间可能抛了一次就出现了正面,也可能抛了n次才出现正面。无论抛了多少次,只要出现了正面,就记录为一次试验。这个试验就是伯努利试验。
进行n次伯努利试验,意味着会有n次的正面。假设每次伯努利试验所经历了的抛掷次数为k。第一次伯努利试验,次数设为k1,以此类推,第n次对应的是kn。
在这n次伯努利试验中,必然会有一个最大的抛掷次数k,例如最多的抛了12次才出现正面,那么称这个为k_max,代表抛了最多的次数。
伯努利试验容易得出有以下结论:
- n 次伯努利过程的投掷次数都不大于 k_max
- n 次伯努利过程,至少有一次投掷次数等于 k_max
最终结合极大似然估算的方法,发现在n和k_max中存在估算关联:n = 2^(k_max) 。
例如:
- 第一次试验: 抛了3次才出现正面,此时 k=3,n=1
- 第二次试验: 抛了2次才出现正面,此时 k=2,n=2
- 第三次试验: 抛了6次才出现正面,此时 k=6,n=3
- 第n次试验:抛了12次才出现正面,此时我们估算,n = 2^12
当试验次数很小的时候,就会出现误差很大的情况,如上面的三次试验。
估算优化
LogLog算法
LogLog的算法是通过增加试验轮次,再取k_max平均数进行估算。我们以3组试验为一轮估算,然后进行100轮或者更多轮次的试验,然后再取每轮的k_max累加,再取平均数,即: (k_max_1 + ... + k_max_m)/m,最终再估算出n。下面就是LogLog的估算公式:
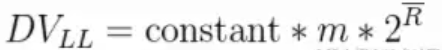
上面公式的DVLL对应的就是n,constant是修正因子,它的具体值是不定的,可以根据实际情况而分支设置。m代表的是试验的轮数。头上有一横的R就是平均数:(k_max_1 + ... + k_max_m)/m。
HyperLogLog算法
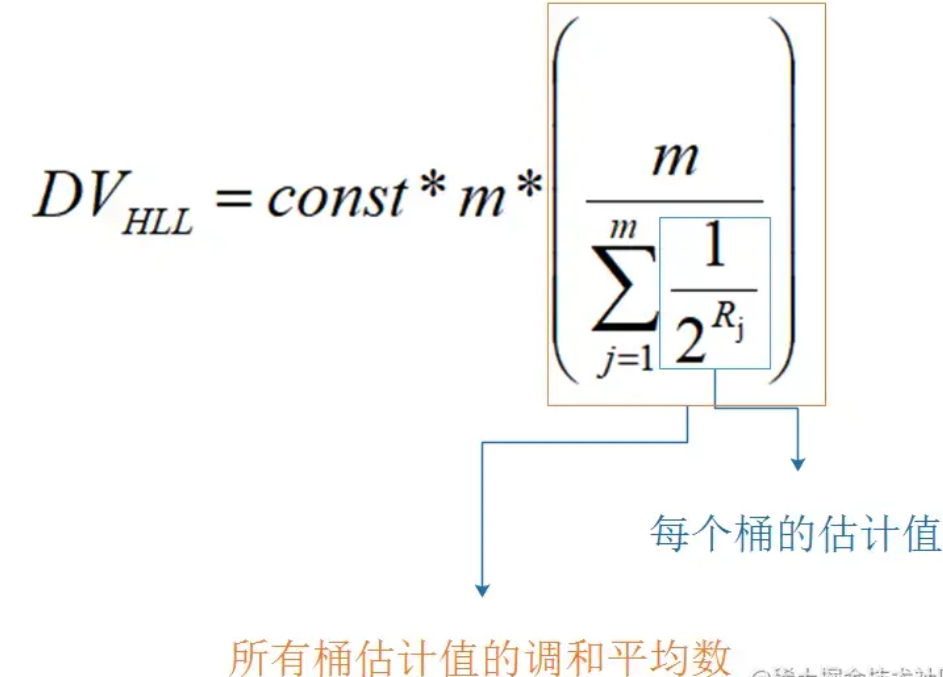
而HyperLogLog和LogLog的区别就是,它采用的不是平均数,而是调和平均数。下面是调和平均数的计算方式,∑ 是累加符号。

调和平均数比平均数的好处就是不容易受到大的数值的影响。下面举个例子:
- A的是1000/月,B的30000/月,求平均工资:
- 采用平均数的方式就是: (1000 + 30000) / 2 = 15500
- 采用调和平均数的方式就是: 2/(1/1000 + 1/30000) ≈ 1935.484
明显地,调和平均数比平均数的效果是要更好的。
HyperLogLog应用
那么在实际过程中,我们是怎么利用HyperLogLog来实现UV统计的。当我们输入一个userId时,会经过以下的几个步骤:
转二进制
通过hash函数,将userId转为二进制形式,例如输入5,便转为:101。套入伯努利试验,0代表了硬币反面,1代表了硬币正面。如果一个数据最终被转化了 10010000,那么从右往左,从低位往高位看,首次出现1的时候,就是正面。
那么基于上面的公式:n = 2^(k_max),我们可以通过多次抛硬币实验的最大抛到正面的次数来预估总共进行了多少次实验。那么也就可以根据多个存入的数据中,转换成二进制后的出现了 1 的最大的位置 k_max 来估算存入了多少数据。
分桶
分桶就是分多少轮。在一个长度为L,单位为bit的大数组S中 ,将S平均分为m组。m组对应多少轮,然后每组所占有的比特个数是平均的,为 P。则:L = S.lengthL = m * p
以 K 为单位,S 占用的内存 = L / 8 / 1024
以Redis HyperLogLog为例:m=16384,p=6,L=16384 * 6,占用内存为=16384 * 6 / 8 / 1024 = 12K
- 第0组 第1组 …. 第16383组
- [000 000] [000 000] [000 000] [000 000] …. [000 000]
这 6 个 bit 自然是无法容纳桶中所有元素的,它记录的是桶中元素数量的对数值,即对应上面提到的k_max。
当每一个元素到来时,它会散列到其中一个桶,以一定的概率影响这个桶的计数值。因为是概率算法,所以单个桶的计数值并不准确,但是将所有的桶计数值进行调合均值累加起来,结果就会非常接近真实的计数值。
存储过程
以前文提到的UV统计为例,首先我们需要将用户ID进行一次二进制转换,即:
- hash(id) = 二进制数字
每一个二进制数字为一次伯努利试验。
然后,计算这个二进制数字所处桶的位置,即分桶。我们假设用二进制数字的前多少位(从右往左,低位往高位看)转为10进制后,其值就对应于所在桶的标号。假设用低两位来计算桶下标志,此时有一个用户ID对应的二进制数是:1001011000011。它的所在桶下标为:11(2) = 1*2^1 + 1*2^0 = 3,处于第3个桶,即第3轮中。
计算出桶号后,剩下的二进制串是:10010110000,从低位到高位看,第一次出现 1 的位置是 5 。也就是说,此时第3个桶或第3轮的试验中,k_max = 5,注意这里取的是首次1的位置index值。
5 对应的二进制是:101,又因为每个桶有 p 个比特位。当 p>=3 时,便可以将 101 存进去。
当然存进去之前,会比较新的index是否比原index大。是,则替换。否,则不变。
模仿上面的流程,多个不同的用户 id,就被分散到不同的桶中去了,且每个桶有其 k_max。当要统计UV时候,就是一次估算。最终结合所有桶中的 k_max,代入估算公式,便能得出估算值。
偏差修正
在估算的计算公式中,constant 变量不是一个定值,它会根据实际情况而被分支设置,例如下面的样子。
假设:m为分桶数,p是m的以2为底的对数。
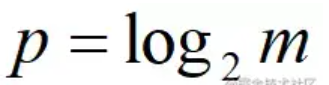
1 | // m 为桶数 |
Redis HyperLogLog的原理
在Redis的实现中,设有 16384 个桶,即:2^14 = 16384,每个桶有 6 位,每个桶可以表达的最大数字是:2^5+2^4+...+1 = 63 ,二进制为: 111 111 。
在存入时,value 会被 hash 成 64 位二进制数字,前 14 位用来分桶,前 14 位的二进制转为 10 进制就是桶标号。假设一个字符串的前 14 位是:00 0000 0000 0010,其十进制值为 2。那么转化后会放到编号为 2 的桶。
对于剩下的50 位,找出首次出现1位置的index值,然后将该index转换为二进制。
极端情况下,出现 1 的位置,是在第 50 位,即位置是 50。此时 index = 50。此时先将 index 转为 2 进制,它是:110010 。
每个桶是 6 bit 组成的,刚好 110010可以被桶中去了。
如果出现不同的 value,会被设置到同一个桶的,即前 14 位值是一样的,但是后面出现 1 的位置不一样。那么比较新的 index 是否比原 index 大。是,则替换。否,则不变。
Redis HyperLogLog中每一个 key 都对应了 16384 个桶,每个桶有一个k_max。其中value 被转为 64 位二进制,64 位转为十进制就是:2^64,HyperLogLog 仅用了:16384 * 6 /8 / 1024 = 12K 存储空间就能统计多达 2^64 个数。
但是在计数比较小的时候,大多数桶的计数值都是零。如果12k字节里面太多的字节都是零,那么这个空间是可以适当节约一下的。Redis在计数值比较小的情况下采用了稀疏存储,稀疏存储的空间占用远远小于 12k 字节。相对于稀疏存储的就是密集存储,密集存储会恒定占用 12k 字节。
密集存储结构
不论是稀疏存储还是密集存储,Redis 内部都是使用bit位图来存储 HyperLogLog 所有桶的计数值。
密集存储的结构非常简单,就是连续 16384 个 6bit 串成的bit位图。

那么给定一个桶编号,如何获取它的 6bit 计数值呢?这 6bit 可能在一个字节内部,也可能会跨越字节边界。我们需要对这一个或者两个字节进行适当的移位拼接才可以得到计数值。
假设桶的编号为idx,这个 6bit 计数值的起始字节位置偏移用 offset_bytes表示,它在这个字节内部的起始比特位置偏移用 offset_bits 表示。
1 | offset_bytes = (idx * 6) / 8 |
比如 bucket 2 的字节偏移是 1,也就是第 2 个字节。它的位偏移是4,也就是第 2 个字节的第 5 个位开始是 bucket 2 的计数值。需要注意的是字节位序是左边低位右边高位。
如果 offset_bits 小于等于 2,那么这 6bit 在一个字节内部,可以直接使用下面的表达式得到计数值 val

1 | val = buffer[offset_bytes] >> offset_bits # 向右移位 |
如果 offset_bits 大于 2,那么就会跨越字节边界,这时需要拼接两个字节的位片段。

1 | # 低位值 |
稀疏存储结构
稀疏存储适用于很多计数值都是零的情况。下图表示了一般稀疏存储计数值的状态。

当多个连续桶的计数值都是0时,Redis 使用了一个字节来表示接下来有多少个桶的计数值都是零:00xxxxxx。前缀两个零表示接下来的 6bit 整数值加 1 就是零值计数器的数量,注意这里要加 1 是因为数量如果为0是没有意义的。比如 00010101表示连续 22 个零值计数器。
6bit 最多只能表示连续 64 个零值计数器,所以 Redis 又设计了连续多个多于 64 个的连续零值计数器,它使用两个字节来表示:01xxxxxx yyyyyyyy,后面的 14bit 可以表示最多连续 16384 个零值计数器。这意味着 HyperLogLog 数据结构中 16384 个桶的初始状态,所有的计数器都是零值,可以直接使用 2 个字节来表示。
如果连续几个桶的计数值非零,那就使用形如 1vvvvvxx 这样的一个字节来表示。中间 5bit 表示计数值,尾部 2bit 表示连续几个桶。
它的意思是连续 (xx +1) 个计数值都是 (vvvvv + 1)。比如10101011表示连续4个计数值都是11。注意这两个值都需要加1,因为任意一个是零都意味着这个计数值为零,那就应该使用零计数值的形式来表示。
注意计数值最大只能表示到32,而 HyperLogLog 的密集存储单个计数值用 6bit 表示,最大可以表示到 63。当稀疏存储的某个计数值需要调整到大于 32 时,Redis 就会立即转换 HyperLogLog 的存储结构,将稀疏存储转换成密集存储。

Redis 为了方便表达稀疏存储,它将上面三种字节表示形式分别赋予了一条指令。
- ZERO:len 单个字节表示 00[len-1],连续最多64个零计数值
- VAL:value,len 单个字节表示 1[value-1][len-1],连续 len 个值为 value 的计数值
- XZERO:len 双字节表示 01[len-1],连续最多16384个零计数值
上图可以使用指令形式表示如下:

存储转换
当计数值达到一定程度后,稀疏存储将会不可逆一次性转换为密集存储。转换的条件有两个,任意一个满足就会立即发生转换:
- 任意一个计数值从 32 变成 33,因为VAL指令已经无法容纳,它能表示的计数值最大为 32
- 稀疏存储占用的总字节数超过 3000 字节,这个阈值可以通过 hll_sparse_max_bytes 参数进行调整
计数缓存
HyperLogLog 表示的总计数值是由16384个桶的计数值进行调和平均后再基于因子修正公式计算得出来的。它需要遍历所有的桶进行计算才可以得到这个值,中间还涉及到很多浮点运算。这个计算量相对来说还是比较大的。
所以 Redis 使用了一个额外的字段来缓存总计数值,这个字段有 64bit,最高位如果为 1 表示该值是否已经过期,如果为 0, 那么剩下的 63bit 就是计数值。
当HyperLogLog中任意一个桶的计数值发生变化时,就会将计数缓存设为过期,但是不会立即触发计算。而是要等到用户显示调用pfcount指令时才会触发重新计算刷新缓存。
缓存刷新在密集存储时需要遍历16384个桶的计数值进行调和平均,但是稀疏存储时没有这么大的计算量。也就是说只有当计数值比较大时才可能产生较大的计算量。另一方面如果计数值比较大,那么大部分pfadd操作根本不会导致桶中的计数值发生变化。
这意味着在一个极具变化的 HLL 计数器中频繁调用pfcount指令可能会有少许性能问题。不过Redis作者在这方面做了仔细的压力的测试,发现这是无需担心的,pfcount 指令的平均时间复杂度就是 O(1)。
对象头
HyperLogLog 除了需要存储 16384 个桶的计数值之外,它还有一些附加的字段需要存储,比如总计数缓存、存储类型。所以它使用了一个额外的对象头来表示。
1 | struct hllhdr { |
所以 HyperLogLog 整体的内部结构就是 HLL 对象头 加上 16384 个桶的计数值位图。它在 Redis 的内部结构表现就是一个字符串位图。你可以把 HyperLogLog 对象当成普通的字符串来进行处理。
1 | 127.0.0.1:6379> pfadd codehole python java golang |
但是不可以使用 HyperLogLog 指令来操纵普通的字符串,因为它需要检查对象头魔术字符串是否是 “HYLL”。
1 | 127.0.0.1:6379> set codehole python |
但是如果字符串以 “HYLL\x00” 或者 “HYLL\x01” 开头,那么就可以使用 HyperLogLog 的指令。
1 | 127.0.0.1:6379> set codehole "HYLL\x01whatmagicthing" |
也许你会感觉非常奇怪,这是因为 HyperLogLog 在执行指令前需要对内容进行格式检查,这个检查就是查看对象头的 magic 魔术字符串是否是 “HYLL” 以及 encoding 字段是否是 HLL_SPARSE=0 或者 HLL_DENSE=1 来判断当前的字符串是否是 HyperLogLog 计数器。如果是密集存储,还需要判断字符串的长度是否恰好等于密集计数器存储的长度。
Redis HyperLogLog命令
Redis HyperLogLog常用的命令:
- pfadd key value #将 key 对应的一个 value 存入
- pfcount key #统计 key 的 value 有多少个
HyperLogLog缺点
- 不能像Set一样减少元素
- 不是精准的计数,有一定误差
精准去重计算替补方案
如果是准确的去重,肯定需要用到 set 集合。考虑到元素特别多,单个集合会特别大,所以将集合打散成 16384 个小集合。通过 hash 算法将这个元素分派到其中的一个小集合存储,同样的元素总是会散列到同样的小集合,这样总的计数就是所有小集合大小的总和。当然这里也可以全局的key(String结构),来统计总的元素个数。当元素到来时,使用这种方式精确计数除了可以增加元素外,还可以减少元素。