MySQL主从复制
什么是主从复制
主从复制,是用来建立一个和主数据库完全一样的数据库环境,称为从数据库;主数据库一般是准实时的业务数据库。
主从复制的作用
做数据的热备,作为后备数据库,主数据库服务器故障后,可切换到从数据库继续工作,避免数据丢失。
架构的扩展。业务量越来越大,I/O访问频率过高,单机无法满足,此时做多库的存储,降低磁盘I/O访问的频率,提高单个机器的I/O性能。
读写分离,使数据库能支撑更大的并发。在报表中尤其重要。由于部分报表sql语句非常的慢,导致锁表,影响前台服务。如果前台使用master,报表使用slave,那么报表sql将不会造成前台锁,保证了前台速度。
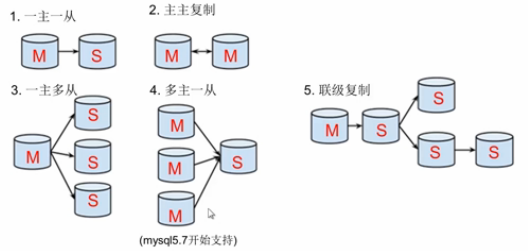
主从复制的形式
mysql主从复制 灵活
- 一主一从
- 主主复制
- 一主多从—扩展系统读取的性能,因为读是在从库读取的;
- 多主一从—5.7开始支持
- 联级复制
主从部署必要条件
- 主库开启binlog日志(设置log-bin参数)
- 主从server-id不同
- 从库服务器能连通主库
- 从库要配置master.info(CHANGE MASTER to…相当于配置密码文件和Master的相关信息)
主从复制的原理
binlog输出线程:每当有从库连接到主库的时候,主库都会创建一个线程,然后发送binlog内容到从库。
在从库里,当复制开始的时候,从库就会创建两个线程进行处理:
从库I/O线程: 当START SLAVE语句在从库开始执行之后,从库创建一个I/O线程,该线程连接到主库并请求主库发送binlog里面的更新记录到从库上。从库I/O线程读取主库的binlog输出线程发送的更新并拷贝这些更新到relay log-中继日志。
从库的SQL线程: 从库创建一个SQL线程,这个线程读取relay log的SQL语句并执行。
可以知道,对于每一个主从复制的连接,都有三个线程。拥有多个从库的主库为每一个连接到主库的从库创建一个binlog输出线程,每一个从库都有它自己的I/O线程和SQL线程。
主从复制如图:

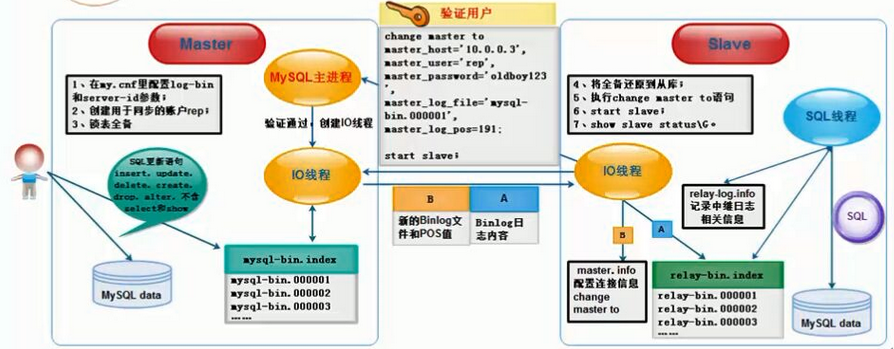
具体步骤:
主库db的更新事件(update、insert、delete)被写到binlog
从库执行start slave命令开启主从复制开关,此时,从库的IO线程会通过在master上已经授权的复制用户权限请求连接master服务器,并请求从执行binlog日志文件的指定位置(日志文件名和位置就是在配置主从复制服务时执行change
master命令指定的)之后开始发送binlog日志内容Master服务器接收到来自Slave服务器的IO线程的请求后,binlog dump 线程会根据Slave服务器的IO线程请求的信息分批读取指定binlog日志文件指定位置之后的binlog日志信息,然后返回给Slave端的IO线程。返回的信息中除了binlog日志内容外,还有binlog中的下一个指定更新位置。
当Slave服务器的IO线程获取到Master服务器上IO线程发送的日志内容、日志文件及位置点后,会将binlog日志内容依次写到Slave端自身的Relay Log(即中继日志)文件(Mysql-relay-bin.xxx)的最末端,并将新的binlog文件名和位置记录到master-info文件中,以便下一次读取master端新binlog日志时能告诉Master服务器从新binlog日志的指定文件及位置开始读取新的binlog日志内容
- Slave服务器端的SQL线程会实时检测本地Relay Log 中IO线程新增的日志内容,然后及时把Relay LOG 文件中的内容解析成sql语句,并在自身Slave服务器上按解析SQL语句的位置顺序执行应用sql语句,并在relay-log.info中记录当前应用中继日志的文件名和位置点
常见问题
联级复制
A->B->C
B中添加参数:1
2
3log-slave-updates #必须要有这个参数
log-bin = /data/3307/mysql-bin
expire_logs_days = 7 #相当于删除7天之后的日志B将把A的binlog记录到自己的binlog日志中
复制出错处理—1062(主键冲突),1032(记录不存在)
- 手动处理
- 跳过复制错误:set global sql_slave_skip_counter=1
Mysql主从复制问题
mysql主从复制存在的问题:
- 主库宕机后,数据可能丢失
- 主库写压力大,从库只有一个sql Thread,复制很可能延时
解决方法:
- 半同步复制—解决数据丢失的问题
- 并行复制—-解决从库复制延迟的问题
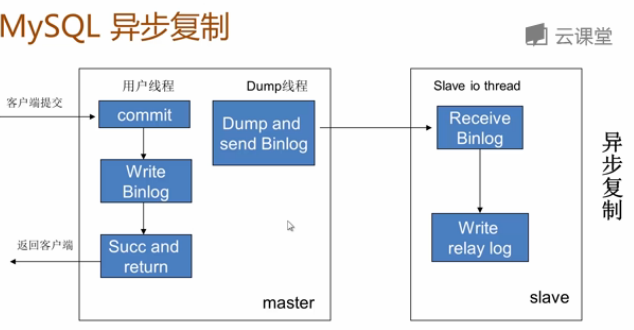
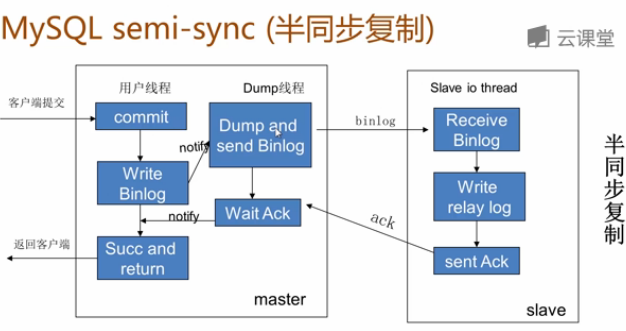
半同步复制
正常的主从复制采用的是异步复制策略。过程如下:
mysql semi-sync(半同步复制)
半同步复制:
- 5.5集成到mysql,以插件的形式存在,需要单独安装
- 确保事务提交后binlog至少传输到一个从库
- 不保证从库应用完这个事务的binlog
- 性能有一定的降低,响应时间会更长
- 网络异常或从库宕机,卡主主库,直到超时或从库恢复
假设有以下架构:介于异步复制和全同步复制之间,主库在执行完客户端提交的事务后不是立刻返回给客户端,而是等待至少一个从库接收到并写到relay log中才返回给客户端。相对于异步复制,半同步复制提高了数据的安全性,同时它也造成了一定程度的延迟,这个延迟最少是一个TCP/IP往返的时间。所以,半同步复制最好在低延时的网络中使用。1
M --S1
并行复制
- 并行是指从库多线程apply binlog
- 库级别并行应用binlog,同一个库数据更改还是串行的(5.7版并行复制基于事务组)
设置sql线程数为101
set global slave_parallel_workers=10;
Mysql主从复制延迟问题原因及解决方法
一个主库的从库太多,导致复制延迟
建议从库数量3-5 为宜,要复制的从节点数量过多,会导致复制延迟
慢SQL语句过多
假如一条SQL语句,执行时间是20秒,那么从库执行完毕,到从库上能查到数据也至少是20秒,这样就延迟20秒了
SQL语句的优化一般要作为常规工作不断的监控和优化,如果是单个SQL的写入时间长,可以修改后分多次写入,通过查看慢查询日志或show full processlist 命令找出执行时间长的查询语句
主从库之间的网络延迟
主库的网卡、网线、连接的交换机等网络设备都可能成为复制的瓶颈,导致复制延迟,另外,跨公网主从复制很容易导致主库复制延迟。
主库读写压力大,导致复制延迟
主库硬件要搞好一点,架构的前端要加buffer以及缓存层。通过read-only参数让从库只读访问 。
- 在my.cnf里[mysqld]模块下加read-only参数,然后重启数据库。
1 | [mysqld] |
对于一致性要求高的可以读写都在主库上,对于读多的,可以在数据库上层添加缓存,面对高并发读。
从库提升主库步骤
确保所有relay log全部更新完毕
在每个库执行1
2stop slave in_thread(sql线程);
show processlit;直到看到Has read all relay log;表示从库更新都执行完毕;
登录从库提升为主库
mysql主从复制中,需要将备库(从库)提升为主库,需要取消其从库角色,可以通过执行以下命令:1
2stop slave;
reset slave all;RESET SLAVE ALL是清除从库的同步复制信息,包括连接信息和二进制文件名、位置
从库上执行这个命令后,使用show slave status将不会有输出进到数据库数据目录,删除master.info relay-log.info
1
2cd /data/3306/data
rm -rf master.info relay-log.info开启binlog
1
2
3
4vim /data/3306/my.cnf
log-bin = /data/3306/mysql-bin
#如果存在log-slave-updates read-only等一定要注释掉它。
/data/3306/mysql restart到此为止,提升主库完毕
其他从库操作
1
2
3
4stop slave;
CHANGE MASTER TO MASTER_HOST ='192.168.1.1'; #如果不同步,就指定位置点。
start slave;
show slave status\G